OraNetted is a Oracle RDBMS based web scrapper application inspired by webharvest.
I have used webharvest for a while but all the scripted glue code to keep
things (cron -> sql to get url parameters -> webharvest ->
insert data into database) in sync was not comfortable. So OraNetted is
a all in one place solution, from scheduling to processing all the data. It has a
plug in system which is extend able with PL/SQL, Java or C/C++.
The Development status is alpha, the application can be installed
from source or by a database dump. The source code is managed with OraSVN.
Visual Concept of OraNetted:
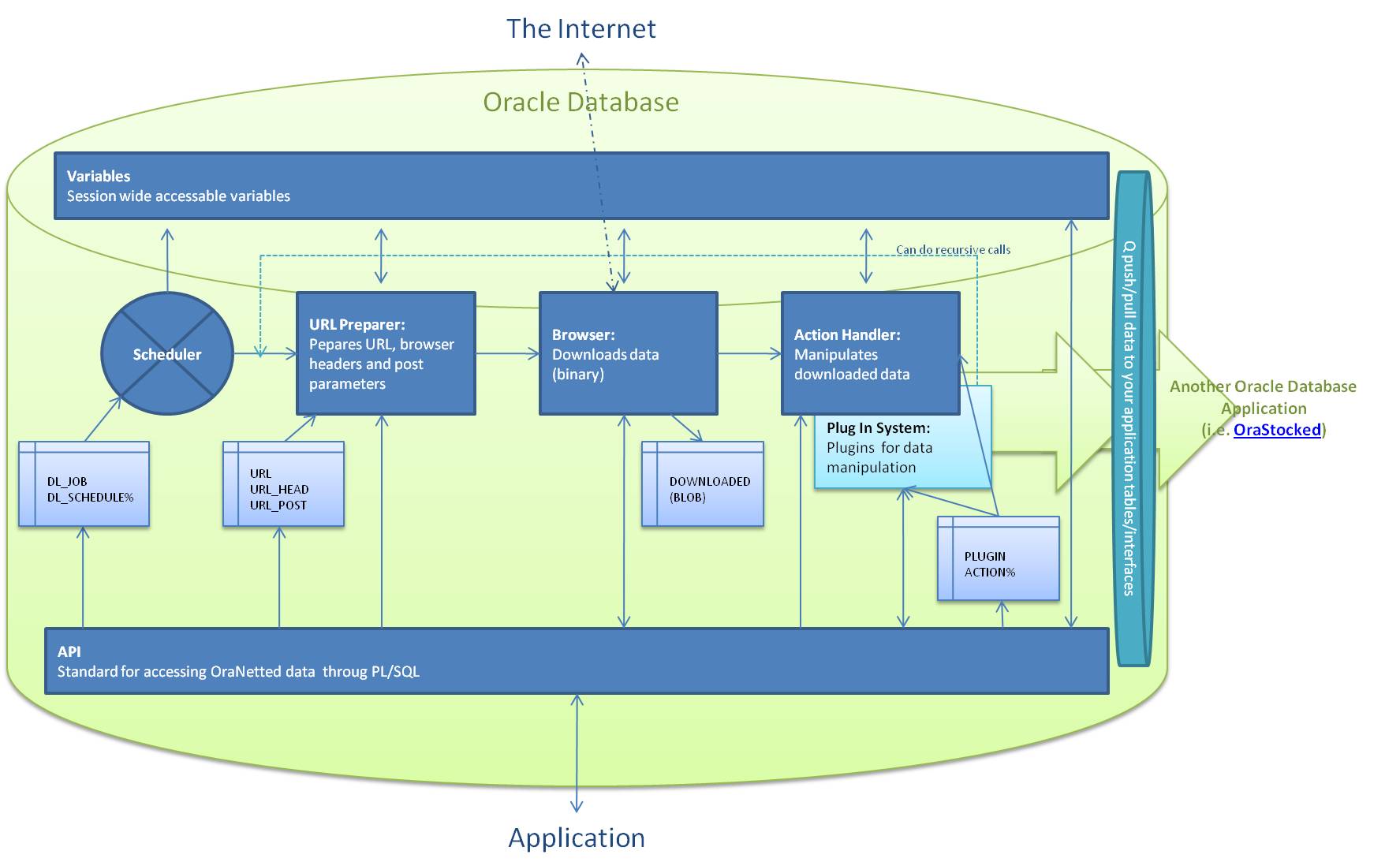
Redo Concept:
Every step from executing a scheduled job to parsing the downloaded
data can be redone. Since every download (binary compressed) and its
parameters (get/post) is stored you can every time re-download or re
execute actions with a single command.
Variables:
You can use varialbes in URL, URL-Header,Post-Parameters and in your
Action-XML. There are two types of variables simple ones (i.e.
${simple_variable}) and function based variables (i.e. $${sysdate}).
Note: variables are stored as varchar2(4000). So no Objects or LOBs are
supported at this time. There are some workarounds:
- If you need Objects you can serialize them (via xml) using
XMLType.toObject function.
- For LOBs you can pass your varibale piece wise or as an ID of a clob stored in a temp
table.
Variables can be set and read via variable# package. Variables can also
be set in the download procedure using: download.url('your_url',
'your_vairable=lala,another_variable=23'), by the netted_api or via var tag in the actionml
Action Handler:
The parsing actions are defined in a XML document (webharvest like).
You can use this following actions. As a
scripting engine you can use pl/sql syntax code.
If non of those action fits your needs you can develop your own plug in
using C/C++, PL/SQL or Java (note: Java is not available in Oracle XE).
A plug in developer tutorial will be found here.
Sample Action XML:
<action>
<convert.blob2clob>
<convert.html2xmltab>
<plsql type_in="number" type_return="number">
declare
begin
for tupl in (
select attr_val from xml_tag_attr where mod(id,1) = content
and attr='href' and attr_val like '%.csv')
loop
--dbms_output.put_line(tupl.attr_val);
netted_api.add_schedule(
i_url_name => 'scoach_eod2'
,i_url_parameters => 'target=' || tupl.attr_val
,i_calender_string => null
,i_parent_id =>
variables#.get_val('current_downloaded_id')
);
end loop;
return content;
end;
</plsql>
</convert.html2xmltab>
</convert.blob2clob>
</action>
More details working with action handler is described in the OraNetted wiki.
PL/SQL Html DOM:
Since html is not xml, xml parsing will fail in the most issues. The
really bad is, even when you clean xml trough tidy
or something similar you will potentially run into XML
exceptions. In example when some xml attribute values exceed 4000 chars
(see http://www.scoach.ch/ 's html code in example). So OraNetted
contains a simple (not fully featured but good enough) pl/sql
implementation of a html dom. Html gets parsed into relational
temporary tables (xml_tag_val and xml_tag_attr). From here you can
query your prior html with simple SQL, you should be able to do the
most XPath queries with SQL.
Here are
Some Screenshots:
Defining a URL with one Variable

Defining an Action holding a function based Variable and a simple one

Executing the Downloader
